こんにちは。ATOM 事業部エンジニアの田村です。
ATOM ではデータ集計に AWS EC2 を利用しています。
負荷に応じて Auto Scaling で小さい集計用インスタンスを起動して分散処理しているのですが、たまに妙にパフォーマンスが上がらないインスタンスができることがありました。
全体の処理に影響するほどではないので、気にはなりつつ調査を後回しにしていたところ、別件の調査中にたまたまその原因を発見したため、原因究明までと対策について書きました。
結論
EBS のバーストクレジット枯渇による IOPS 低下が原因でした。CloudWatch のメトリクス BurstBalance でクレジット残量を確認できます。
これは EBS のメトリクスなので、確認するにはインスタンスに繋がっているボリューム ID が必要なのですが、短命のインスタンスができてすぐ削除されるような状況ではボリュームIDを特定しづらいのが難点です。
こういった場合は、まだオープンプレビュー中の機能ですが CloudWatch Metrics Insights によるメトリクスのクエリを利用すると便利です。
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/query_with_cloudwatch-metrics-insights.html
調査
たまたま別件の調査中に、妙に長時間起動しっぱなしのインスタンスを見つけました。 インスタンス数は Auto Scaling によって増減するので、基本的に長命なインスタンスはあまり見かけません。 珍しいので調べていたら、これがたまに発生する「パフォーマンスが上がらないインスタンス」であることがわかり、時間は限られますがついでに調査することにしました。
CloudWatch でメトリクスを見てみます。
CPU
 まず
まず CPUUtilization を見てみましたが、概ね 80〜90% ぐらいを維持できていて CPU が有効に使われている状態です。
最後の方でグラフが下がっているあたりが、パフォーマンス低下している部分のようです。
t 系のインスタンスタイプではないため、 CPU バーストクレジットは存在しないので気にする必要はありません。 怪しいのは I/O 系ですね。
ストレージ
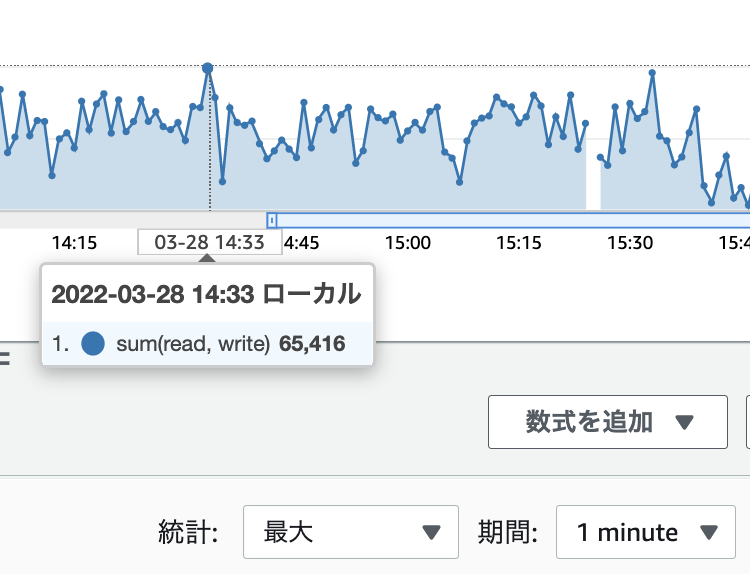 IOPS を確認します。
Read と Write の合計はピーク時に 65,416 (毎分) なので 65,416 / 60 秒 = 約 1090 IOPS です。
IOPS を確認します。
Read と Write の合計はピーク時に 65,416 (毎分) なので 65,416 / 60 秒 = 約 1090 IOPS です。
 ボリュームは gp2 30GB なので IOPS は最低ラインである 100 なのですが、 1000 IOPS 以上出ているのは EBS のバーストクレジットのおかげですね。
ボリュームは gp2 30GB なので IOPS は最低ラインである 100 なのですが、 1000 IOPS 以上出ているのは EBS のバーストクレジットのおかげですね。
ん? そういえば EBS のバーストクレジット残量って監視できてないよな・・・?

EBSIOBalance% を見てみましたが 100 〜 99% を行ったり来たりで、意味があるグラフには見えません。 クレジットが枯渇したらこのグラフが動くと思っていたのですが、ここには大した変化がないようで、このメトリクスの見方がちょっとわかりませんでした。
・・・ここでふと気がついて、EBS ボリューム ID で EBS のメトリクス BurstBalance を見てみました。
 これですね。
綺麗に右肩下がりになっていて、最終的にほぼ枯渇寸前になっています。
完全に 0 になっていない点に疑問が残りますが、この辺を深堀りし始めると長そうなので(別件の調査中なのもあり)これ以上はまた別の機会にします。
これですね。
綺麗に右肩下がりになっていて、最終的にほぼ枯渇寸前になっています。
完全に 0 になっていない点に疑問が残りますが、この辺を深堀りし始めると長そうなので(別件の調査中なのもあり)これ以上はまた別の機会にします。
対策
コンスタントに 1000 IOPS 以上を維持する方法を検討します。
gp2 の場合ストレージサイズを増やすことで IOPS 上限は上がりますが、1000 以上を維持するには 333 GiB 以上必要なので、現在の 30 GiB より大幅にコストが増えてしまいます。
2020/12 に新たに発表された gp3 に切り替えることで 最大 3000 IOPS にできますが、スループット上限が gp2 より低かったり、処理の内容によってはレイテンシが上がるケースもあるらしく、検証なしで導入するのはちょっと不安です。
https://aws.amazon.com/jp/ebs/volume-types/
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/ebs-volume-types.html
別の方法として、インスタンスが起動している時間を短かくすることで、バーストクレジットが枯渇する前にインスタンスが終了する方法も検討します。 処理の内容が変わらないかぎりクレジット消費ペースが大幅に変わることはないので、インスタンス起動時間が短かければクレジットが枯渇する可能性は大幅に低くなるはずです。
Auto Scaling グループの設定を確認したところ「高度な設定」の項目にそれらしいものがありました。
「終了ポリシー」を確認します。
終了ポリシーとは「どのインスタンスを最初に終了するか」を制御するものですが、現在 Default に設定されています。
Default の挙動はドキュメントの記述によると
(抜粋) 次の課金時間に最も近い保護されていないインスタンスが複数ある場合、これらのインスタンスのいずれかをランダムに終了します。
たまに長時間生き残るインスタンスができてしまったのは、終了するインスタンスがランダムに決定された結果のようです。
バーストクレジットを最も消費しているであろう、最も古いインスタンスから終了したい場合は OldestInstance が良さそうです。
https://docs.aws.amazon.com/ja_jp/autoscaling/ec2/userguide/ec2-auto-scaling-termination-policies.html#default-termination-policy
また「インスタンスの最大存続時間」も設定できます。 現在のインスタンス利用状況なら終了ポリシーだけでもほぼ枯渇は防げそうですが、こちらも設定しておくとさらに確実になりそうです。 (2022-03-31 追記: この設定を試してみたところ、設定できる値は最低 86,400 秒 = 1日以上 だったので、今回のような数時間で終了させたい場合には利用できませんでした)
今回のようにインスタンスができて短時間で削除されるような状況だと、問題が発生したボリューム ID の特定は難しく、動的に生成されるインスタンスに紐づくリソースをうまく監視する方法はないものか・・・と思っていたら、最近出てきた新機能 CloudWatch Metrics Insights が使えそうです。 これはまだオープンプレビュー中の機能ですが、今回のようなケースにはとても有効で、例えば以下のようなクエリで、バーストクレジットが枯渇しそうなボリューム上位10件をメトリクスにすることができます。
SELECT MIN(BurstBalance) FROM SCHEMA("AWS/EBS", VolumeId) GROUP BY VolumeId ORDER BY MIN() ASC LIMIT 10
 このように、クレジット枯渇が近いボリューム上位10件をメトリクスにできます。 これは便利!
このように、クレジット枯渇が近いボリューム上位10件をメトリクスにできます。 これは便利!
おわりに
パフォーマンス低下の原因は単純なクレジット枯渇でしたが、Auto Scaling によって起動されるインスタンスの監視は難しく、グループメトリクスで見える情報も限られているのが悩みの種でした。 しかし CloudWatch Metrics Insights を利用することで、動的に監視対象を変えることができ監視の幅が広がりそうです。