はじめに
こんにちは、ATOM 事業部のエンジニアの岸田 (@mwudo) です。
普段は API の開発や基盤の改修をしたり、リポジトリ内で使うコードの自動生成を行う仕組みを Go で書いています。
ATOM の API サーバに AWS X-Ray を導入したので、その際に行ったことについて実装などを示しながら紹介したいと思います。
導入背景
ATOM では各媒体が公開しているAPIを使用して広告のクリック数やコンバージョン数などの実績値をバッチ処理で毎日取得しています。
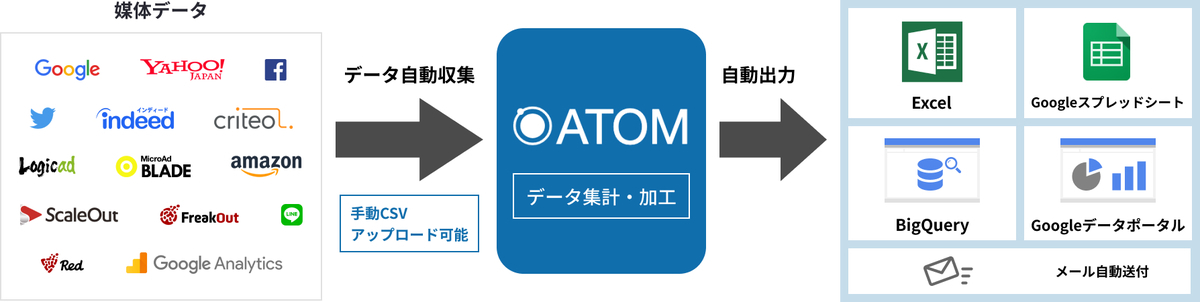
外部の API を使用している関係で取得に時間がかかる問題に対しても、レスポンスが遅いのか、あるいは自分たちで実装した処理が効率が悪く時間がかかってしまっているのかの二軸がすぐに考えられると思います。
今回挙げた二軸それぞれで解決方針が異なりますし、ATOM を使ってくださっているお客様への情報共有の仕方も違ってくると思います。
運用しているシステムだと問題の切り分けが難しく報告するまでに時間を要する状況でした。
そこで、AWS X-Ray を導入することでシステムの実行状況を可視化し、ボトルネックとなっている部分を特定して改善するというサイクルをより早く回したり、情報共有のスピードをあげるなどの価値提供できるようしたいと思いました。
本当であれば、最初に紹介した実績値を毎日取得するバッチ処理に導入するところですが、AWS X-Rayを使うのが初めてであることと、媒体のAPIを使う部分が少し複雑な仕組みで動いているので、まずATOM内で稼働している一般的なAPIサーバに対して導入して慣れることからはじめました。
AWS X-Ray とは
アプリケーションの状況(実行時間や発行された SQL など)を収集して分析とデバッグが可能なサービスです。
マイクロサービスだと他の API へのリクエストや S3 や DynamoDB などの AWS のサービスなどを一つの処理の流れで見ることが可能なので、アプリケーション全体のパフォーマンスの分析ができます。
データの収集に関しては、アプリケーションとは別で起動させた AWS X-Ray デーモンに対して SDK を使って行います。
収集したデータを AWS X-Ray デーモンが AWS X-Ray API に定期的に転送を行い AWS X-Ray コンソールに表示される仕組みになっています。
詳しくは AWS から Black Belt の資料が公開されていますので、合わせてご覧ください。
本記事でAWS X-Ray(以下 X-Ray)で使われる単語を使用するので紹介します。
セグメント
処理の動作に関する情報です。例えば API サーバに HTTP リクエストが来た場合は、ホスト名やリクエスト情報、開始時刻や終了時刻、後述するサブセグメントなどがセグメント情報になります。
サブセグメント
セグメント内で行われる、DB の読み書きや外部の API への HTTP リクエストなどの他リソースへの処理の情報です。例えば、DB の読み書きの場合だと発行されたSQLなどがサブセグメントの情報として保存されます。
トレース
一つの処理の中で生成されたセグメントとサブセグメントを束ねたもの、X-Ray のコンソールではトレースの単位で処理を見ることが可能です。
AWS X-Ray SDK について
SDK を使用することで、トレースデータを X-Ray へ送信する処理を SDK 側に任せることができます。
いくつかの言語では SDK が用意されていて、ATOM では Go を使って開発を行っているので AWS X-Ray SDK for Go を使いました。
では AWS X-Ray SDK for Go で使用する処理について簡単に紹介します。
ここではエラーハンドリングの処理とimport文は省略しています。
セグメントの作成方法は大きく分けて2種類あります。
func main() { // 1. context とセグメント名を指定することでセグメントが作られる ctx, seg := xray.BeginSegment(context.Background(), "セグメント名") // セグメントでの処理を終えた時 seg.Close(nil) // 2. http.Handler か http.HandlerFunc にラップする場合 xray.Handler(xray.NewFixedSegmentNamer("セグメント名"), http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {})) }
セグメントが作成されると、context にセグメント情報が保存されて後続の処理に伝搬させていきます。
xray.BeginSegment だと ctx に、xray.Handler だと http.Request.ctx です
サブセグメントの作成方法は使用用途によっていくつか用意されていています。
func CreateSubsegment(ctx context.Context) { // xray.BeginSegment と同じ形 subCtx, subSeg := xray.BeginSubsegment(ctx, "サブセグメント名") // ある一連の処理に対して作成する場合 err := xray.Capture(ctx, "サブセグメント名", func(context.Context) error{...}) // DB をトレースする場合 (db の型は *sql.DB) db, err := xray.SQLContext("ドライバー名", "DBへの接続情報") // http.Client の場合 client := xray.Client(&http.Client{}) // AWSサービスの場合(例:S3) sess, err := session.NewSession() s3Service := s3.New(sess) xray.AWS(s3Service.Client) }
注意しなければならないことが、サブセグメントを作る時は必ずセグメント情報が保存された context を使う必要があります。
サブセグメントを作る際に ctx を渡していないものは
contextを引数にもつ関数を使わなければなりません。例:
db, err := xray.SQLContext(...)だと、db.QueryContext(ctx, query, args)
セグメント情報がないと、処理の流れを紐付けができなくなります。
もし、サブセグメントを作る時にセグメント情報がない場合、いくつか振る舞いがあります。
SDKで用意されている振る舞いが3つあります。
| 関数名 | 振る舞い |
|---|---|
ctxmissing.NewDefaultRuntimeErrorStrategy() |
panic |
ctxmissing.NewDefaultLogErrorStrategy() |
logger.Errorf |
ctxmissing.NewDefaultIgnoreErrorStrategy() |
何もしない |
aws-xray-sdk-go/default_context_missing.go at master · aws/aws-xray-sdk-go · GitHub
デフォルトでは ctxmissing.NewDefaultRuntimeErrorStrategy()、つまりセグメント情報がない場合パニックになりますので、他の振る舞いに変更することを必ずしてください!
init() などの処理に変更する処理を入れるとよいと思います。
func init() { err := xray.Configure(xray.Config{ // ContextMissingStrategy がセグメント情報がない場合の振る舞いを決める ContextMissingStrategy: ctxmissing.NewDefaultLogErrorStrategy(), }) if err != nil {...} }
ContextMissingStrategyはctxmissing.Strategyという interface なので、ご自身で自作可能です。
実装例
SDKの処理をそのままアプリケーションの実装に入れるとローカルの開発やCIでのテストの実行時でも X-Ray デーモンを起動させる必要があります。
これはかなり開発者体験がよろしくないので、interface 経由で使用するようにします。
package tracing import (...) // 各関数は 紹介した AWS X-Ray SDK の関数と対応しています type Tracer interface { RDB(driver, dsn string) (*sql.DB, error) AWS(client *awsClient.Client) HttpClient(client *http.Client) *http.Client Handler(name string, handler http.HandlerFunc) http.Handler Capture(ctx context.Context, name string, fn func(ctx context.Context) error) error }
例えば、Tracer.Handler を使う場合は http.HandlerFunc に対して一つずつ適用するよりも、ミドルウェアとして入れるほうが効率的です。
package middleware import (...) type TracingMiddleware struct{} // ミドルウェアを適用する順番にお気を付けください func (m *TracingMiddleware) Handle(next http.HandlerFunc) http.HandlerFunc { return func(w http.ResponseWriter, r *http.Request) { tracing.Handler("セグメント名", next).ServeHTTP(w, r) } }
http.Request.RequestURIの値や認証方法によってセグメント名を変えることもできます。
interface を使用することで、例えば X-Ray の処理は呼ばず引数の値をそのまま戻り値に返すような処理を用意し、ローカルやCIの環境はそちらに切り替えることで普段の開発の邪魔にならないです。
Tracer.Handler だと以下のようなイメージです。
type tracer struct {} // Handler はラップするフリをしてそのまま hander を返す func (f *tracer) Handler(_ string, handler http.HandlerFunc) http.Handler { return handler }
さらに interface にすることでちょっとしたことができて、Capture という処理で以下のようなことができます。
// Capture は fn の実行時間を標準出力に出す func (f *tracer) Capture(ctx context.Context, name string, fn func(ctx context.Context) error) error { start := time.Now() err := fn(ctx) elapsed := time.Since(start) fmt.Fprintf(os.Stdout, " [TRACE][%s] %s\n", name, elapsed) return err }
本来は
type tracer struct { out io.Writer}を用意してoutにos.Stdoutが入る形になると思います。もちろん
os.Stdoutの部分をio.Discardにすることで出力を破棄することもできます。
導入後
現在、本番環境でのAPIサーバに X-Ray を導入して動かしていますが、いくつか効果があった場面がありました。
具体的には、本番環境で context canceled のエラーが出ている原因を X-Ray のトレース情報から特定し修正を行いました。
他には、あるエンドポイント内で行われる DB から1レコード取得するような SQL の実行が普段なら数十ミリ秒なのがまれに数百ミリ秒にまで遅くなることを X-Ray のトレース情報から発見しました。
トレース情報に記録されていた時間帯から、システムの裏で実行されているデータ移行周りが悪さをしているのではないかということがわかりました。
発生頻度も稀で、数十ミリから数百ミリ秒の変化であること、レスポンスを返すまでの時間もユーザ側が動作が遅く感じるほどでは無かったので、顕在化しにくい現象だったと思います。
今回紹介した2つの事例を通して、「推測するな、計測せよ」 という言葉が思い浮かびました。
さいごに
今回はAPIサーバに X-Ray を導入しましたが、本来は広告の実績値を取得する処理に X-Ray を入れることが目的でした。
バッチ処理は AWS Batch で動かしている関係で、APIサーバの時とは導入の方法が少し異なります。
How to configure AWS X-Ray tracing for your AWS Batch jobs | AWS Cloud Operations & Migrations Blog
バッチ処理にも導入し、運用して共有できる情報があれば、記事として公開できればと思います。
この記事が X-Ray の導入の一助となれば嬉しいです。
最後まで読んでいただきありがとうございました。