はじめに
こんにちは。 2023年6月までデータ戦略室でDBエンジニアとして所属していて、 7月からライクル事業部に異動になりました小宮です。
以前所属していたデータ戦略室ではデータを加工するTransformツールとしてdbtを使っていました。 今回はGCP(Google Cloud Platform)でもTransformツールとして有名なDataformが最近GAになったので使ってみました。
Dataformとは
Dataformとは、BigQueryのためのフルマネージドなデータパイプライン管理ツールで、ELT(Extract/Load/Transform)のTransformに特化しています。 テーブル間の依存関係を管理しながらテーブルやビューをテスト・開発・デプロイすることができます。
Dataformは元々Dataform社が独自で開発していたサービスですが、 2021年にGoogleに買収され約2年間の統合期間を経て 2023/05/04にGAとなった比較的新しいサービスです。
無料で利用することができます。
Dataformを使うと何が嬉しい?
従来はBigQueryのデータを加工する際はスケジュールされたクエリや保存されたクエリなどを使う必要がありました。
何か分析依頼があった場合などに 最終的なアウトプットに必要のない中間テーブルを作成するクエリやビューが大量にでき、 後で見返すとよくわからない。 みたいなことが結構起きたりします。
さらに、次はこういう粒度で見たいなどの要望により頻繁に変更が起きがちです。
Dataformでは標準でGitと統合されていてバージョン管理が容易にできたり、 自動でクエリの依存関係を持たせたりできるので頻繁な変更にも対応しやすいです。
そのほかにも、データの品質テストを自動で行う機能や、Javascriptを使用してコードを再利用可能にすることもできるので、 個人利用だけでなく大きなシステムのデータパイプラインにも組み込む恩恵は大きいです。
Dataformのファイル構成
ベストプラクティスの例を参考にご説明します。
Dataformではクエリをdefinitionsの中に定義します。
その際サブフォルダとして以下のような各データ層ごとのフォルダを作成することを推奨しています。
特にこの例に沿わなくても問題ありませんが、 保守性や可読性の観点からこの構成にしておいた方が良さそうです。
. ├── definitions/ │ ├── reporting #データマート層 │ ├── sources #データレイク層 │ └── staging #データウェアハウス層 ├── includes/ ├── .gitignore ├── dataform.json ├── package-lock.json └── package.json
sources(データレイク層)
Dataformで管理するテーブルを定義します。 ここではdeclarationを使ってテーブルを定義するのみで集計クエリなどは配置しません。
-- test_table.sqlx config { type: "declaration", database: "project-id", schema: "dataset", name: "test_table" }
Dataformのクエリで直接SELECT * FROM project-id.dataset.tableのように書くことはできますが、直接参照だとデータリネージで自動的に可視化されないので利用するテーブルはここで定義することをお勧めします。
declarationで定義しておくとSELECT * FROM ${ref(test_table)}という書き方で参照できます。
staging(データウェアハウス層)
中間テーブルのクエリを主に配置します。最終的なアウトプットにはならないクエリです。
実際にやってみたパートで登場するfirst_viewがこの層に該当します。
-- first_view.sqlx config { type: "view", columns: { test: } } SELECT 1 as test
reporting(データマート層)
最終的なアウトプットを作成するクエリを配置します。BIツールに接続するためのデータマートや集計結果として出力するようなクエリです。
-- second_view.sqlx config { type: "view" } SELECT test from ${ref("first_view")}
実際に使ってみた
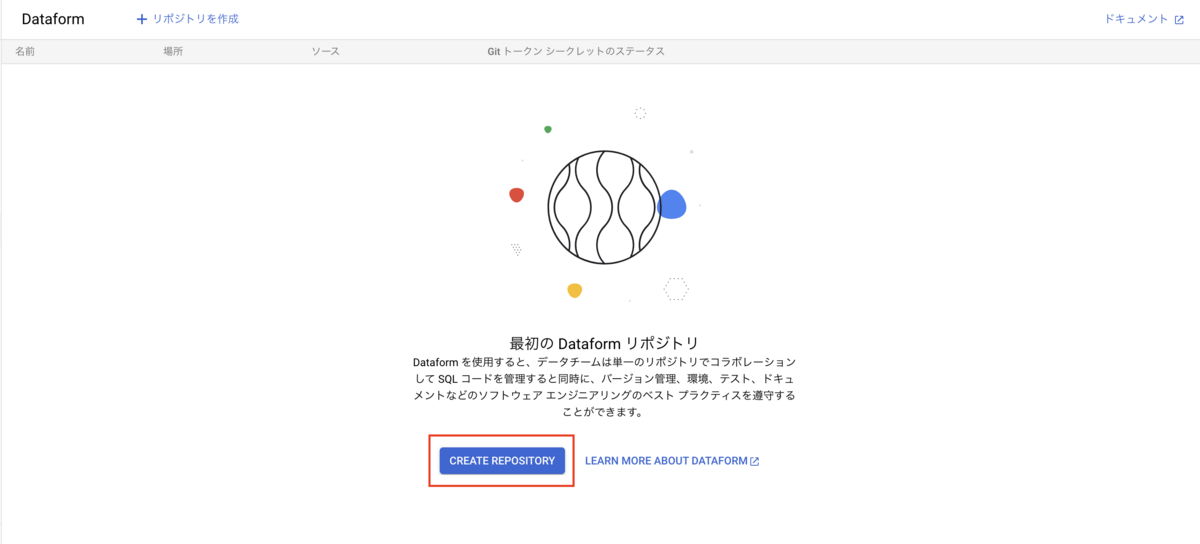
リポジトリ作成
まず最初にDataformでのプロジェクトを始めるにあたり、リポジトリを作成します。
これはコードを保存・管理する場所で、プロジェクトのベースとなります。
権限の付与
リポジトリが作成されるとGoogleが管理するサービスアカウントが作成されます。
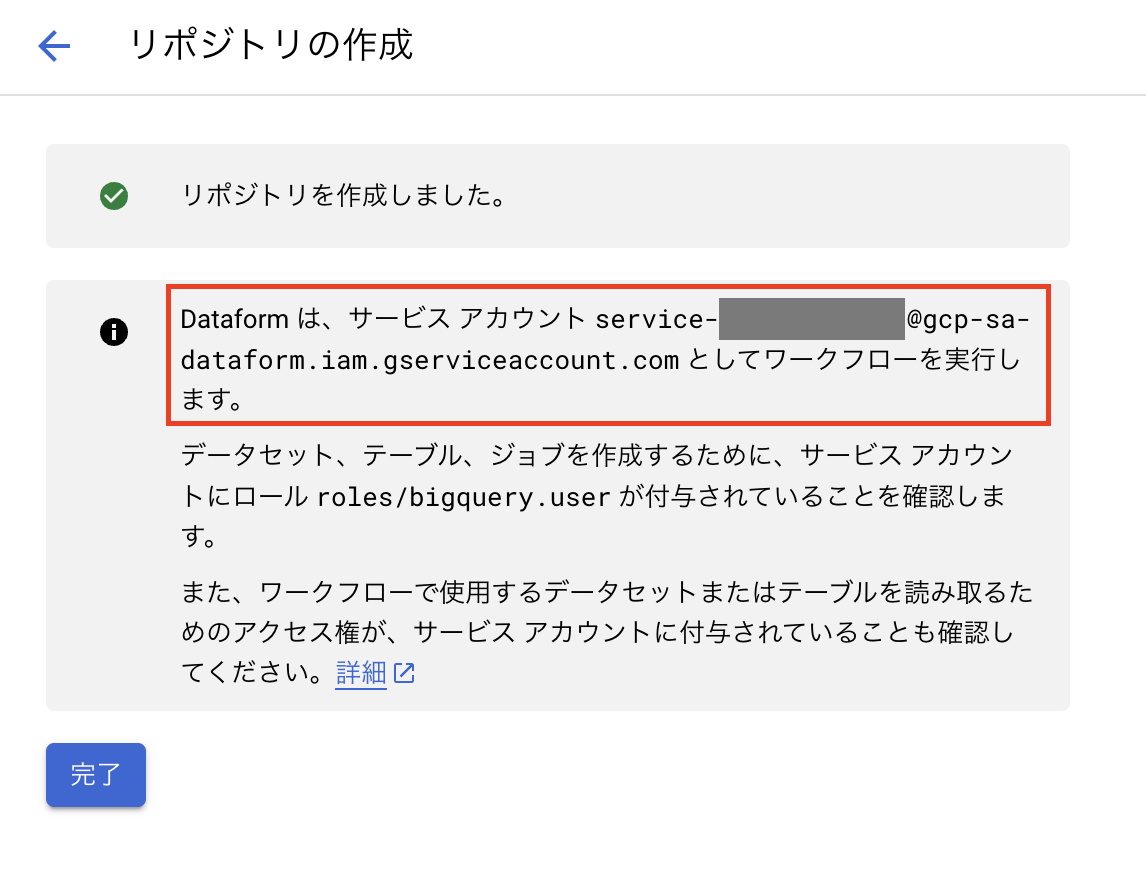 このサービスアカウントに対して以下の権限を付与する必要があります。
このサービスアカウントに対して以下の権限を付与する必要があります。
- BigQuery データ閲覧者
- BigQuery データ編集者
- BigQuery ジョブユーザー
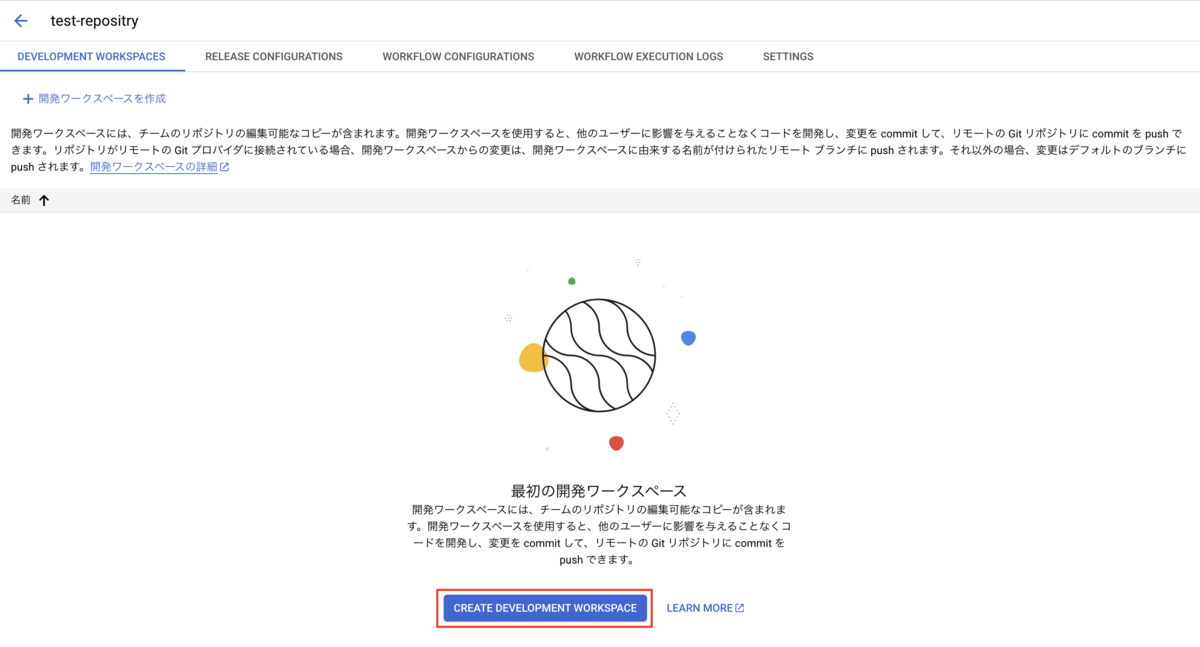
ワークスペース作成
次に、作成したリポジトリに対応するワークスペースを作成します。
ワークスペースは、特定のリポジトリのデータを操作できる環境で、ここで実際のコードの作成や編集を行います。
複数のワークスペースを作成することで、一つのリポジトリに対して複数人で同時に開発することができます。
ワークスペース初期化
ワークスペースが作成されたら、その環境を初期化します。
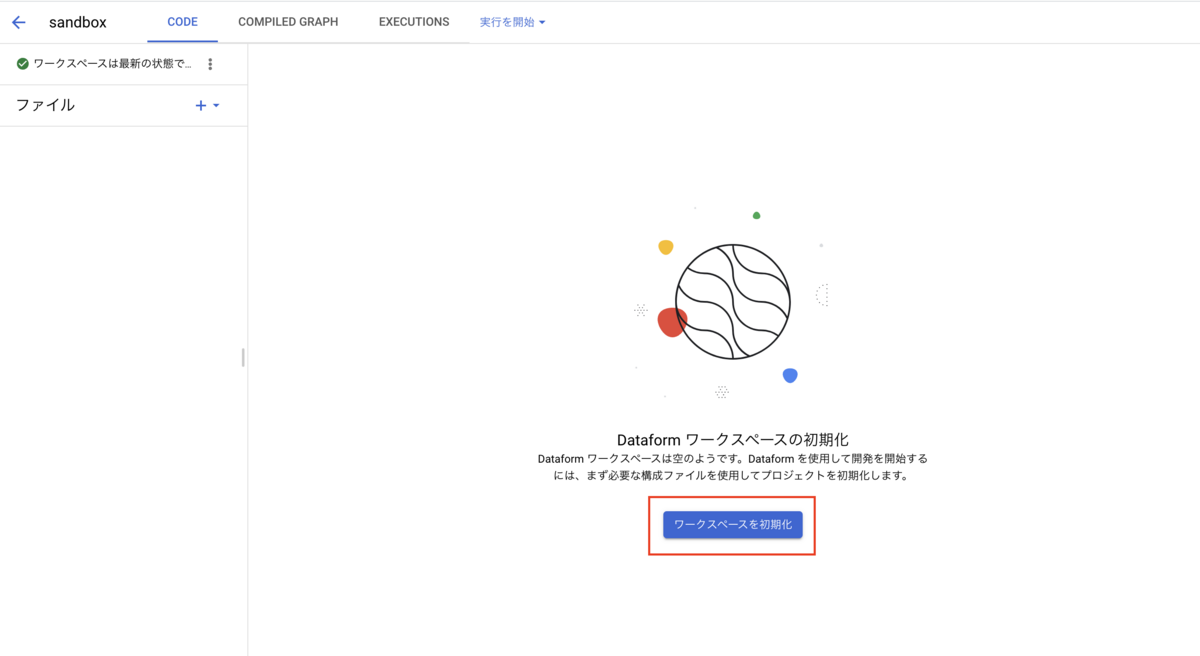
初期化を行うとDataformに必要な最低限のファイルとサンプルクエリが作成されます。
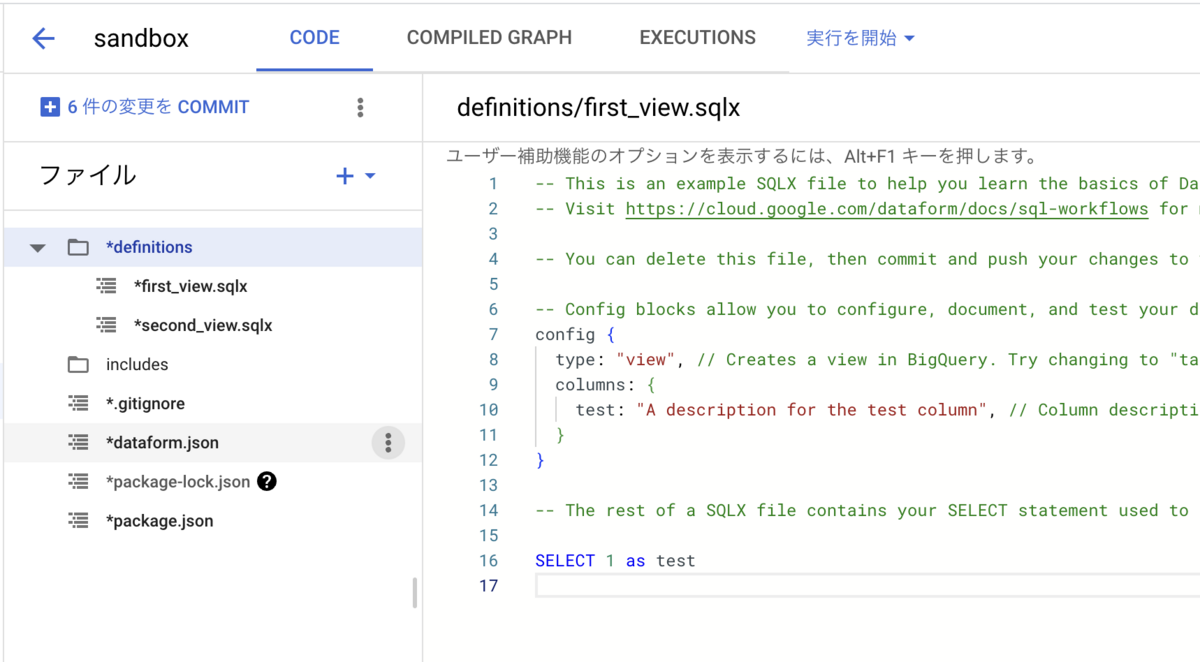
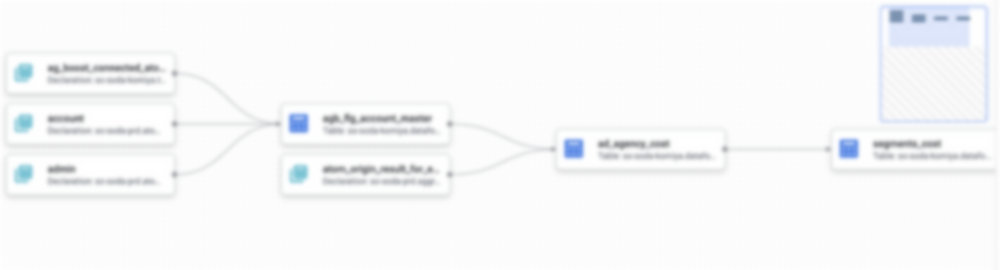
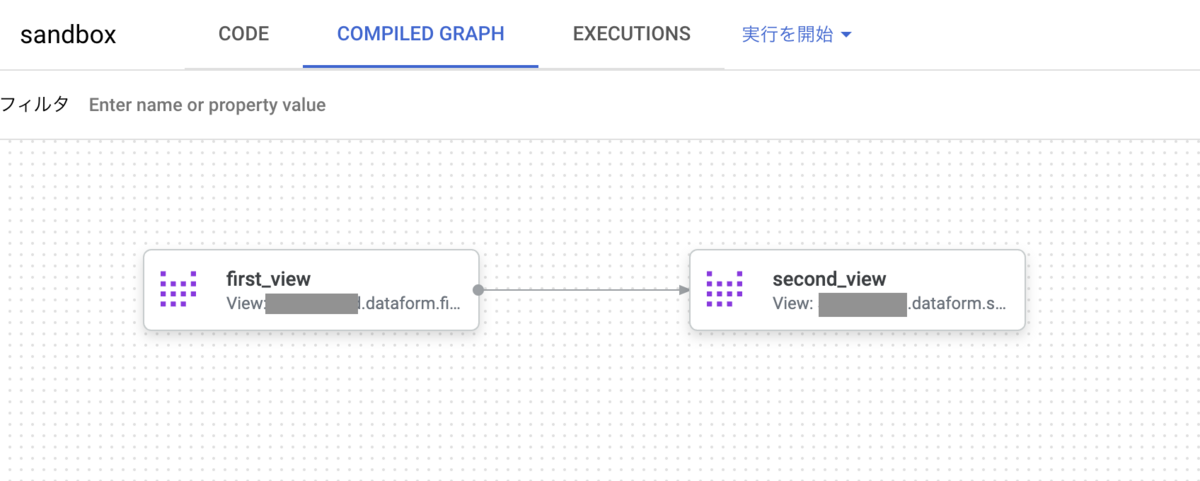
この状態のままCOMPILED GRAPHを確認するとサンプルクエリのデータリネージを確認できます。
first_viewをもとにsecond_viewが作成されていることが一目でわかります。
実行
実行メニューから実行したいアクション(クエリ)を選択します。
今回はsecond_viewを作成します。 依存関係を含めるを選択しておくと、second_viewに依存関係がある全てのテーブルを作成し直します。(今回だとfirst_viewも作り直す)
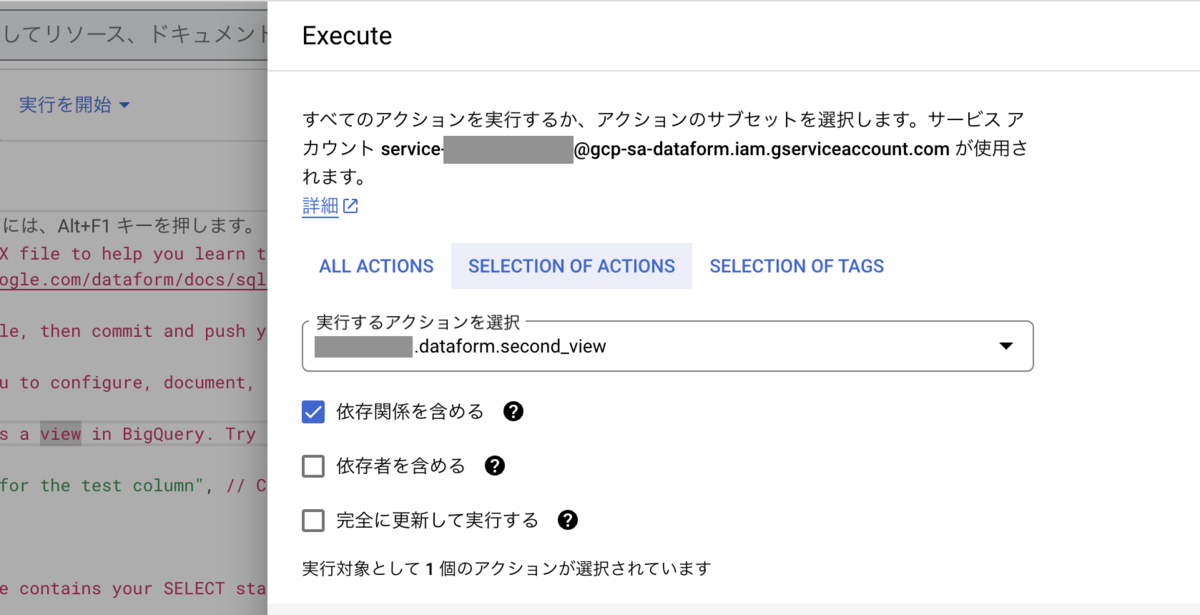
無事作成されました。デフォルトではdataformというデータセットを自動で作成し、その中にテーブルを作成します。
作成できました。簡単です。
おわりに
Dataform最高です。Transformationツールとして非常に使いやすいのでBigQueryをデータ基盤にしているのであればぜひ使ってみてください。