はじめまして
こんにちは、データ戦略室の伊藤です。最近はデータ基盤の保守や改修を中心に担当しています。
今回はタイトルの通り、ChatGPT等のLLMを外部データと接続することができるLlamaIndexを試してみました。 非常にシンプル&短めのコードですので、もしよろしければ皆様の環境でもお試しいただければと思います。
LlamaIndexとは
LlamaIndexは、上述の通りLLMと外部データを接続し、LLMに与えたデータをベースとした回答をさせることができるライブラリです。 よく名前が挙げられるLLMライブラリとしてLangchainがありますが、LlamaIndexはLangchainの機能の中でもデータの取り込み(データコネクタ)やデータの構造化(データインデックス)部分に特化しています。
提供されているデータコネクタは、CSVやPDF等各種ファイルはもちろん、NotionやSlack、Discord等があります。 詳しくは公式ドキュメントをご覧ください。
動かしてみる
Slackアプリの作成
まず、Slackの情報を取得するためにSlackアプリを作成する必要があります。 既に色々な分かりやすい記事があるかと思いますが、本記事でも改めて手順についても紹介いたします。
- Slack API: Applications | Slackにアクセスし
Create New Appをクリック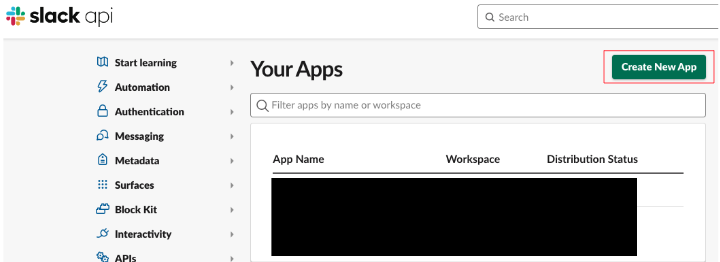
From scratchをクリック- アプリ名と対象のワークスペースを入力し、
Create Appをクリック - アプリの作成後、左のサイドバーから
OAuth & Permissionsをクリック - User Token Scopesに以下4つのスコープを追加

- 同じ
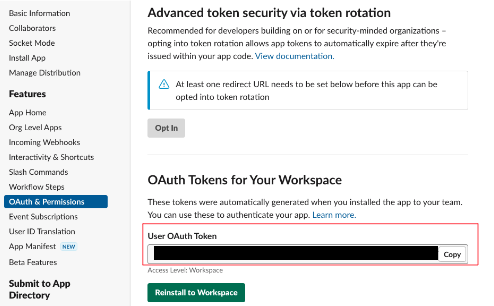
OAuth & Permissions画面上部のInstall to Workspaceをクリック
ここまでの手順が完了したら、Bot User OAuth Tokenが発行されます。このトークンを使用することで、Slackの情報を取得できるようになります。
LlamaIndexのインデックス&エンジンの作成
自分はGoogle Colaboratory上で実行しましたが、ローカル環境でも問題ないです。コードは以下の通りです。
# パッケージのインストール
!pip install -q llama-index slack_sdk
from llama_index import SummaryIndex, SlackReader from IPython.display import Markdown, display import os slack_token = "<先ほど発行したBot User OAuth Token>" channel_ids = ["<取得対象のチャンネルID>"] os.environ["OPENAI_API_KEY"] = "<OpenAIのAPIキー>" slack_reader = SlackReader(slack_token=slack_token) documents = slack_reader.load_data(channel_ids=channel_ids) index = SummaryIndex.from_documents(documents)
コードは非常にシンプルでこれだけなのですが、対象チャンネルのデータ量が多すぎるとSlackのレート制限に達してしまい、以下のようなエラーが出てしまいます。
ERROR:llama_index.readers.slack:Rate limit error reached, sleeping for: 10 seconds
その場合は、以下のように期間を指定してデータ量を絞ることで、APIのコール回数を減らしてあげると良さそうです。
import datetime dt_now = datetime.datetime.now() latest_date = dt_now earliest_date = latest_date - datetime.timedelta(weeks=2) slack_reader = SlackReader(slack_token=slack_token, earliest_date=earliest_date, latest_date=latest_date)
また、作成したインデックスはファイル形式で保存し、別の環境で使用することも可能です。
# インデックスの保存 index.storage_context.persist(persist_dir="./storage") # インデックスの読み込み from llama_index import StorageContext, load_index_from_storage index = load_index_from_storage(StorageContext.from_defaults(persist_dir="./storage"))
質問テスト
テストとして、Yahooニュースから持ってきた大谷選手の記事をSlackに投稿し、その内容について質問してみました。

query_engine = index.as_query_engine() response = query_engine.query("大谷の今季のOPSは?") display(Markdown(f"<b>{response}</b>"))
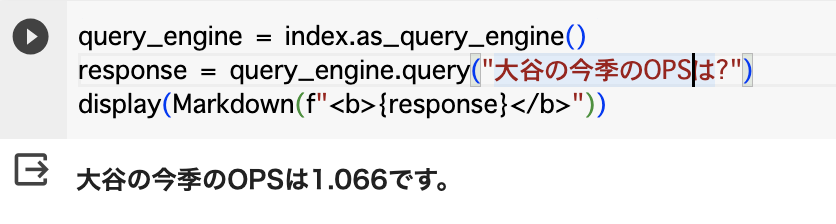 きちんと与えたデータを参考に正確な数字を回答してくれていますね。
きちんと与えたデータを参考に正確な数字を回答してくれていますね。
おわりに
今回は、LlamaIndexとそのデータコネクタSlackReaderを使用する例を紹介いたしました。少しでも参考になれば幸いです。
ただ、実際に社内の他チャンネルでも試してみたところ、データ量が増えると質問内容に類似した参考データを見つけられずに回答ができなかったり、 (当たり前ですが)ニュース記事と違ってデータが整理されていないので関係のない内容を拾ってしまったりと課題も多く、実運用まで持っていくにはもう少し工夫が必要だと感じています。 これらの課題をどうクリアしていくかについては、引き続き考えていきたいと思います。
最後まで読んでくださり、ありがとうございました。