はじめに
こんにちは、数ヶ月ほど前からCTO室に異動した伊藤です。
今回はLangfuseを用いたLLMアプリケーションのモニタリングについて紹介いたします。
Langfuseとは
Langfuseは、LLMアプリケーションの開発者がトレースや評価、プロンプト管理、メトリクス等を使用してアプリケーションのパフォーマンスを向上させるためのツールです。
公式サイト: https://langfuse.com/
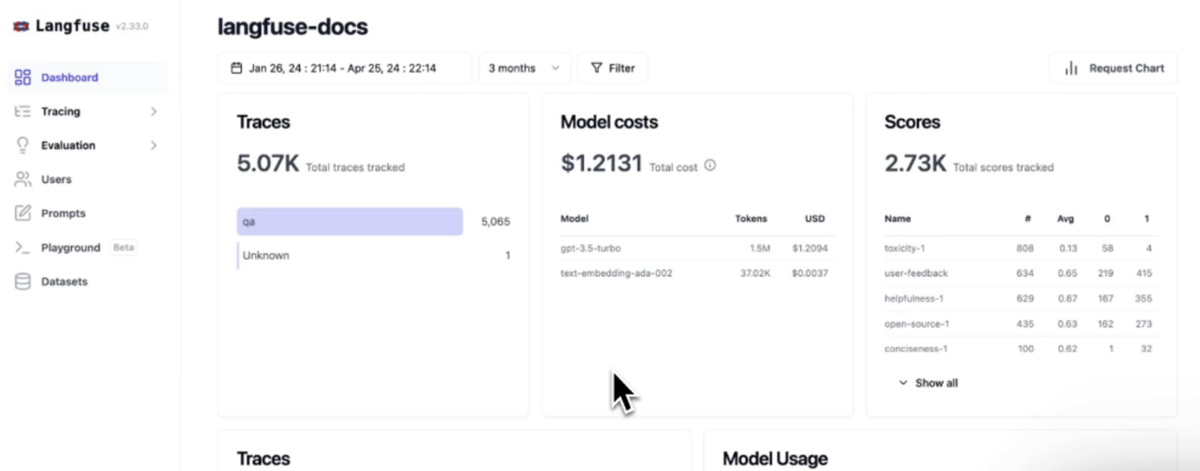
各機能の詳細については以下の通りです。
- トレース:
- 各LLMの呼び出しと関連ロジックの詳細ログを取得し、処理の流れを追跡
- プロンプト管理:
- プロンプトのバージョン管理と変更履歴の追跡
- 応答評価:
- 評価指標やユーザーフィードバックを用いてモデルの応答品質を評価
- メトリクス収集:
- 応答時間や使用料金等を記録し、ダッシュボードにて可視化
また、Langfuseと同じような他のLLMアプリケーションの管理ツールとして、LangSmith等も挙げられます。 その中で、LangfuseはSaaSとしてLangfuse Cloudが提供されている他にDockerを利用したセルフホストも可能となっている点がポイントです。
動かしてみる
公式ドキュメントには2つの手順が記載されています。
- ローカル
- docker composeを使用
- LangfuseとDBのコンテナをそれぞれ作成
- docker composeを使用
- セルフホスト
- LangfuseのDockerイメージを使用
- Postgresについては、別途用意が必要
- 本番環境で用いる際は、ECSやCloudRun等のマネージドサービスにコンテナをデプロイ
本記事では、本番環境を想定してCloudRunにデプロイするセルフホストの手順を紹介いたします。
※余談になりますが、ローカルにてdocker composeを使用する手順において、LLMアプリケーションを別コンテナ上で実行している場合はコンテナ間のnetworkを繋いだり、後ほど触れる環境変数LANGFUSE_HOSTをコンテナ名orコンテナidに変更したりする必要があるので、ご注意ください。
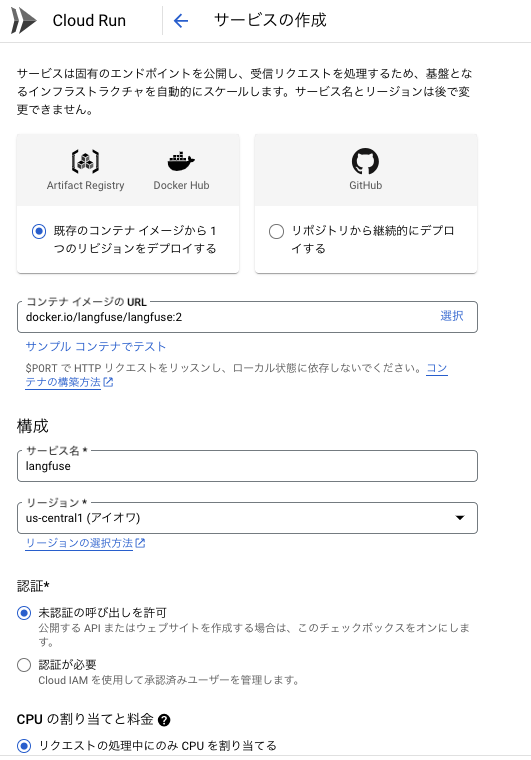
1. CloudRun上でLangfuseコンテナを起動
公式ドキュメントの手順に従って、サービスを作成します。 設定する環境変数については、以下の通りです。
- DATABASE_URL
- 別途用意したPostgresデータベースの接続文字列
- NEXTAUTH_URL
- 最初のデプロイ時は仮の文字列として
http://localhost:3000を設定 - デプロイ後に[新しいリビジョンの編集とデプロイ] から生成されたCloudRunサービスのURLに更新
- 最初のデプロイ時は仮の文字列として
- NEXTAUTH_SECRET
- ログインセッションクッキーを検証するために使用
openssl rand -base64 32にて生成
- SALT
- ハッシュ化されたAPIキーにソルトを追加するために使用
openssl rand -base64 32にて生成

2. LangfuseのWeb画面上で初期設定
サービスを作成しNEXTAUTH_URLの更新も完了したら、実際にURLにアクセスします。
最初は認証画面が表示されるので、SignUpからアカウントを作成し、プロジェクトの作成等の設定を進めます。
Setting→Create new API keysからAPIキーを作成し、表示された認証情報をメモしておきます。
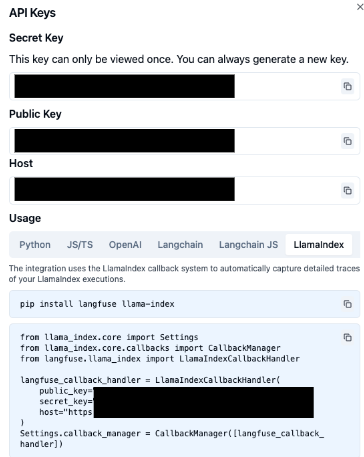
3. LLMアプリケーション(LlamaIndex)とLangfuseの連携
Langfuse側の設定が終わったら、実際にLLMアプリケーション側からLangfuseにトレースができるよう設定を進めます。 本記事ではLlamaIndexを使用する場合の手順を紹介します。 とは言っても、こちらも手順が公式ドキュメントに書かれていて、僅か数行のコードを追加するだけです。
なお、今回はLlamaIndexによるLLMアプリケーションの作成手順は割愛いたしますが、こちらについては以前別の記事にて紹介させていただきましたので、もしよければご覧ください。
import os from dotenv import load_dotenv from langfuse.llama_index import LlamaIndexCallbackHandler from llama_index.core import Settings, StorageContext, load_index_from_storage from llama_index.core.callbacks import CallbackManager load_dotenv() langfuse_callback_handler = LlamaIndexCallbackHandler( //ここからの数行がLangfuseを追加するための差分 public_key=os.getenv("LANGFUSE_PUBLIC_KEY"), secret_key=os.getenv("LANGFUSE_SECRET_KEY"), host=os.getenv("LANGFUSE_HOST"), ) Settings.callback_manager = CallbackManager([langfuse_callback_handler]) storage_context = StorageContext.from_defaults(persist_dir="[インデックスファイルの保管パス]") index = load_index_from_storage(storage_context) chat_engine = index.as_chat_engine(similarity_top_k=2) question = "[質問内容]" response = chat_engine.chat(question) print(response.response)
これで設定は完了です。 LangfuseのWeb画面から、ダッシュボードやRAGの回答生成過程を確認できるようになります。
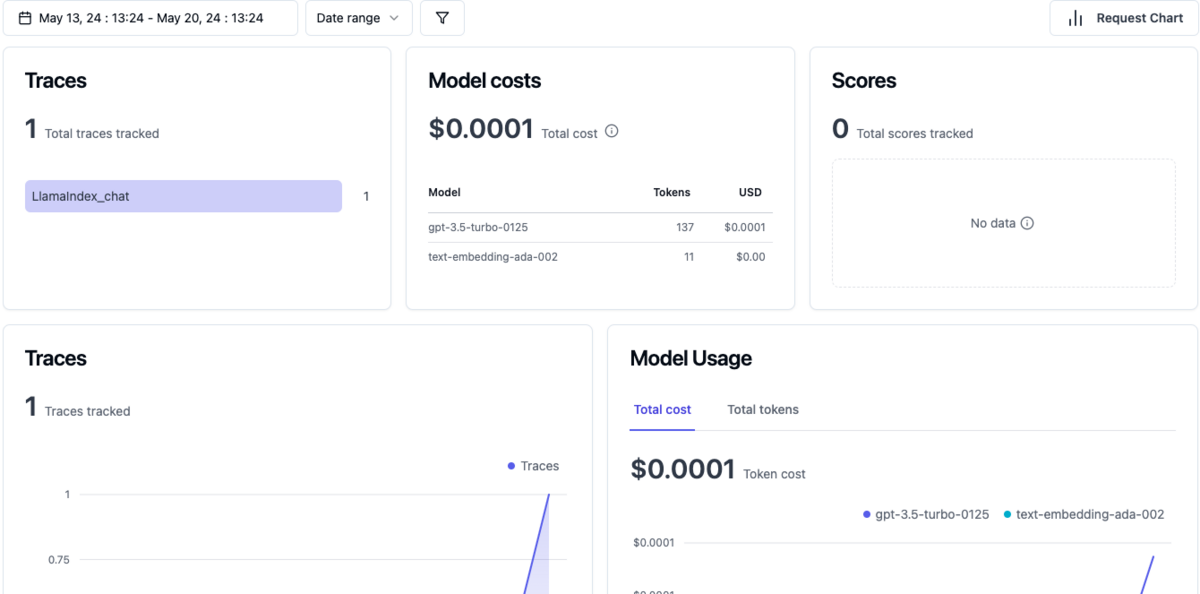
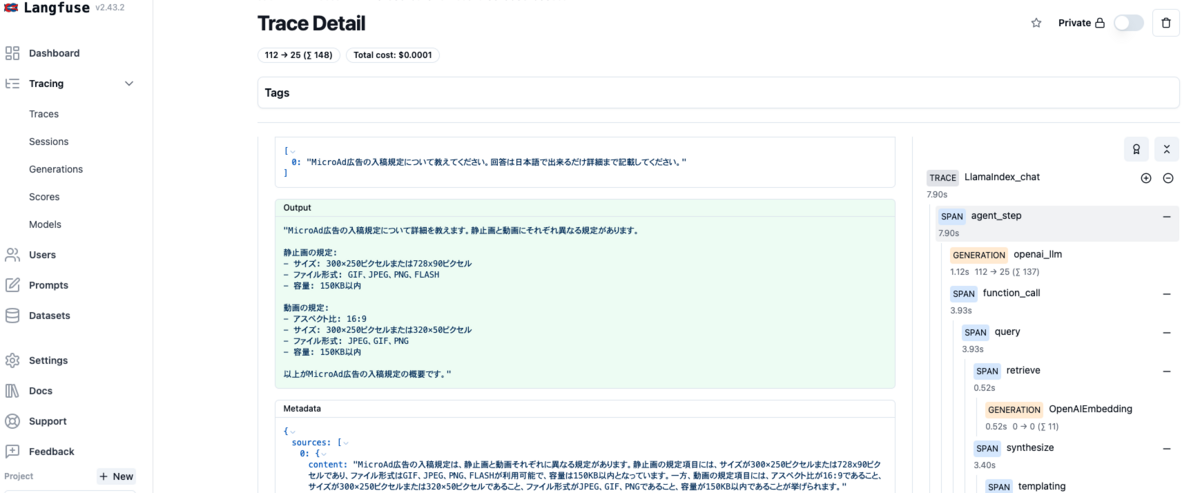
4. パラメータや応答評価指標の追加
上記のコードに以下の数行を追加することで、ユーザー IDやセッション ID、タグ等の追加のパラメータをトレースに追加できます。
langfuse_callback_handler.set_trace_params(
user_id="user-123",
session_id="session-abc",
tags=["production"],
version="1.0.0",
release="1.0.0",
)

応答評価指標については、LlamaIndex+RAGASの組み合わせを使う場合ドキュメント通りにいかず少しだけ大変でした。 パラメータと同じような手順でスコアをトレースに追加することはできないので、一度トレースした後にスコアを追加する必要があります。 参考までに私がやってみた時のコードを記載します。
▼コード(長くなってしまうため折りたたみ)
import itertools import os import time from datasets import Dataset from dotenv import load_dotenv from langfuse.llama_index import LlamaIndexCallbackHandler from llama_index.core import Settings, StorageContext, load_index_from_storage from llama_index.core.callbacks import CallbackManager from ragas import evaluate from ragas.metrics import answer_relevancy, faithfulness load_dotenv() langfuse_callback_handler = LlamaIndexCallbackHandler( public_key=os.getenv("LANGFUSE_PUBLIC_KEY"), secret_key=os.getenv("LANGFUSE_SECRET_KEY"), host=os.getenv("LANGFUSE_HOST"), ) langfuse_callback_handler.set_trace_params( user_id="user-123", session_id="session-abc", tags=["production"], version="1.0.0", release="1.0.0", ) Settings.callback_manager = CallbackManager([langfuse_callback_handler]) storage_context = StorageContext.from_defaults(persist_dir="[インデックスファイルの保管パス]") index = load_index_from_storage(storage_context) chat_engine = index.as_chat_engine(similarity_top_k=2) question = "[質問内容]" response = chat_engine.chat(question) output = response.response # traceが登録されるまで多少ウェイトを入れる ※ウェイトなしだとトレースが取得できない時がありました time.sleep(10) langfuse = langfuse_callback_handler.langfuse trace_id = langfuse_callback_handler.get_trace_id() trace = langfuse.get_trace(id=trace_id) retrieves = [t for t in trace.observations if t.name == "retrieve"] nodes = list( itertools.chain.from_iterable([retrieve.output["nodes"] for retrieve in retrieves]) ) contexts = [node["node"]["text"] for node in nodes] evaluations = { "question": [question], "contexts": [contexts], "answer": [output], "trace_id": [trace.id], } ds = Dataset.from_dict(evaluations) r = evaluate(ds, metrics=[faithfulness, answer_relevancy]) df = r.to_pandas() df["trace_id"] = ds["trace_id"] for _, row in df.iterrows(): for metric_name in ["faithfulness", "answer_relevancy"]: langfuse.score( name=metric_name, value=row[metric_name], trace_id=row["trace_id"] )

また、パラメータや応答評価指標についてはLangfuseのWeb画面上から手動で追加することも可能です。 本機能を用いて、専門知識を持ったメンバーにWeb上から直接評価してもらうことで、応答の精度向上を目指すような運用もできるかと思います。
おわりに
今回は、LLMアプリケーションをよりパワーアップさせるためのLangfuseの使い方について紹介させていただきました。 セルフホスト版であれば低コストで導入可能なので、是非一度試してみてください。 自分もまだ触れていない機能がいくつかあるので、更に色々と試していこうと思います。
最後まで読んでくださり、ありがとうございました。