こんにちは
ATOM 事業本部のエンジニアの渡部です。
最近ローカル環境でgemma2やllama等のLLMを動かして実際に活用してみたのですが 結構実用レベルの性能が出ましてとても感動しました。
そこで「普段使用しているNeoVimと連携させてAIコーディングしたら更に感動するのではないか?」
と思いやってみることにしました
とはいえ素直にgithub copilotに課金したほうが生産性は上がるとは思いますが、ローカル環境上で動かすメリットも存在します。
そのメリットとして、無料で!ネット環境なしで!サービス依存無しで!使用することができます。
ネットが繋がらないときやgithub copilot等のサービスが落ちたときの代替としても対応できます。
ということで今回はNeoVimとローカル環境下でAIを構築する方法を紹介, 使った感想など共有したいと思います。
ローカルで動くLLMについて
皆さんが一般的に使われているChatGPTやgeminiなどはサーバー上で動いている世間一般で認知されている大規模言語モデル(LLM)です。
これらのLLMのほかに、ローカル環境上で動くLLMがあります。
以下はローカル環境上で動くLLMの代表的なものです。
Llama (Meta)
Gemma (Google)
DeepSeek (DeepSheek)
またコードアシスト特化型AIというのも存在します。
Qwen2.5-Coder
StarCoder2
今回使うもの
PC 今回動かすのは以下の構成です。
Macbook Pro 16 inch
M1 Pro
32GB RAMNeoVim
Vimの拡張版のようなCLI上で動くエディタです。
後述するプラグインはおそらくVimでも使えると思います。llama.cpp
AI言語モデルを動かすためのC++ライブラリです。
https://github.com/ggml-org/llama.cpp/tree/masterggml-org/llama.vim
今回NeoVimで使うプラグインです。
https://github.com/ggml-org/llama.vim
llama.cppのインストール
今回はbrewを使用してインストールします。 llama.cppをインストールするには以下のコマンドを実行してください。
brew install llama.cpp
NeoVimの設定
init.vimに以下の設定を追加してください。
call dein#add('ggml-org/llama.vim')
今回私はdein.vimを使用していますので その場合、dein.tomlファイルに以下を追加します。
[[plugins]] repo = 'ggml-org/llama.vim'
あとはNeoVimを起動して以下のように入力してインストールします。
call dein#install()
実際にコーディングしてみる
- llama.cppを起動する
まずはモデルを指定してサーバーを起動します。
今回はマシンスペックが十分なので7bを使用します。
llama-server --fim-qwen-7b-default
- NeoVimを起動して動作確認
次にNeoVimを起動して、有名なハノイの塔プログラムをほとんどAI任せで記載してみます。
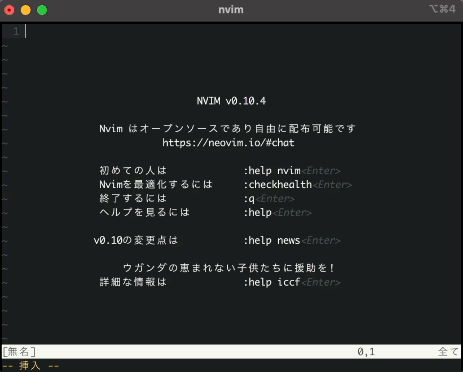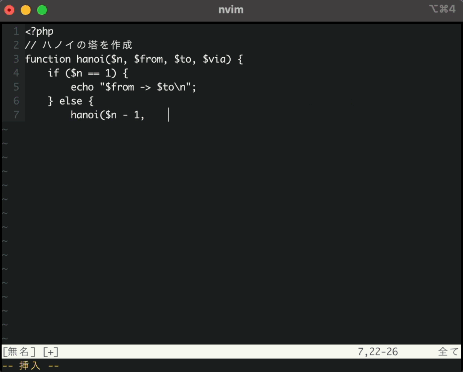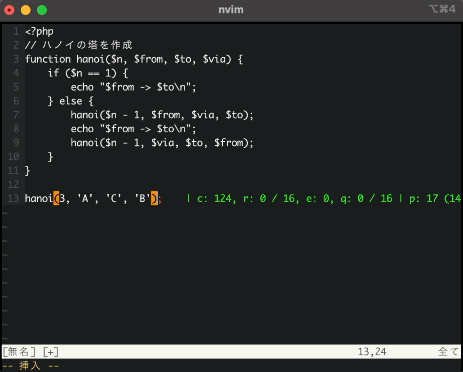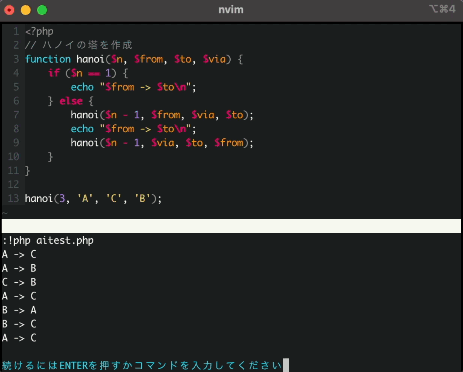
動画は倍速にしていますが、入力から候補を出すまでの時間がかなり早く実用レベルでした。
感想
思ったよりレスポンスは悪くなく、AIコードアシストとしては間違いなく実用レベルに達していました。
しかし一方で、補完後にカーソルの位置が微妙にずれたり、アシスト結果の反映が適切にできなかったりと
洗練されていない印象を受けました。
今回はNeoVimで行いましたがVSCodeにも「Continue」というプラグインがあり、
こちらで似たようなことができるらしいです。
おまけ
この記事を書いている最中にClaude Codeなるものが発表されました。
今回紹介したコードアシストとは違い、ユーザーの指示によって、AIエージェントが主体となってコードを自動的に生成していくものです。
実際に触ってみたのですが、CLI, Webインタフェースを持つアプリケーションができてしまいました。
githubにpushまでやってもらいました結果がこちらです
無料クレジット約4ドルほどを消費しましたがすごい時代になりましたねー